



At the end of the last post, we had these prompts for Deep Research:
“Act as an expert and experienced legal-tech consultant. I need to design a system that ingests various client documents—PDFs (image-based, OCR’d, native), Word files, and chat logs—and helps lawyers quickly see key details. What are the essential user requirements (from a lawyer’s perspective) and the functional requirements (from a technical standpoint) for such a system? Focus on common complaints and gripes from lawyers and other legal practitioners, file parsing, data security, and preserving critical document structure.”
“You are an expert research assistant with expertise in PDF/Word parsing in Rust. You are also a Rust expert. Summarise best practices for handling different PDF types (image-based vs. text-based), .docx files and emails. Maintaining fidelity to document structure is crucial. Include potential libraries, tools, or workflows that are widely used in the industry.”
And the idea here is to build as much context as possible. Chat logs here, and here.
As you’ll see Deep Research asks me clarifying questions first. From a meta perspective, that mirrors what we would expect a good junior/subordinate/staffer would do. In Deep Research, it seems implemented as a necessary step of the workflow: always check whether there are any clarifications to be made, and ask them.
In other words, make it part of a standard workflow.
Another thing to note is that my answers to the questions could easily have been additional research threads. I went ahead to tap on my own experience, but you may want to consider how to further structure the various threads of research.
A lot of what I’ve just written in the preceding paragraphs is about workflow.
The Importance of Workflow & Structured Data
Workflow is huge. And there are several points worth noting here. If you can keep track of your steps—like OCR, extracting text, identifying metadata, chunking text for AI summarization—you’ll have a clearer idea of where errors might crop up.
Often, I see lawyers, and especially lawyers, writing “Do X” type prompts. Which works well on Copilot because that’s how Copilot seems to have been trained. If they do not get the output they want, the model has failed. But again, we come back to the idea of using a tool smartly. I
In some way, this also mirrors how some bosses assign similar “Do X” type tasks. The best juniors come up with their own workflows, processes, and heuristics. But the opportunity is here to make that part of a standard process, rather than an indicator of excellence.
Another point worth noting, is to consider preserving the document’s structure (paragraphs, headers, indentation). Lawyers often rely on that structure to interpret meaning. A bullet point can carry legal significance if it’s enumerating liabilities or disclaimers. Stripping everything down to raw text might lose context or make your final review harder.
Vibe Coding vs. Real Coding Standards
Now, let’s talk about vibe coding, which is basically telling ChatGPT (or some other LLM), “Write me a Python script to parse PDFs.” Then you run it, fix errors, keep going until it’s… passable. It’s a fun introduction—especially for lawyers who don’t code daily—but it’s also a bit wild. Remember: in law, we have house styles, disclaimers, uniform drafting conventions. Programmers have the same concept with code: docstrings, type safety, style guides, testing frameworks, all that good stuff. If we’re aiming for anything beyond a throwaway script, we need to think about those coding standards from Day One.
Vibe coding is a vibe, but it’s also a major trap.
I usually have more steps to develop context, to check veracity, more checks, and chasing up little points, before I jump to the coding prompt. For the purposes of this series I’ll jump ahead.
What I’ll do next is feed these requirements into an agent on Cursor, a programming Integrated Development Environment, that has AI agents and workflows plugged in.
I’ve saved the output from the Deep Research files as .md files to provide context, and so that these form part of the codebase. Ideally, we’ll organise this better.
And we’ll see what it produces with this prompt:
“Generate a Next frontend based on the requirements currently in the codebase.”
Next is arguably the most popular framework for working with one of the main Javascript (programming language) libraries for building user interfaces. I’ve picked it because there’s just so much training material for it, and seems to be the language of choice for other code LLMs like v0.dev
I usually am more specific about the setup I want. For example, my preference, for a variety of reasons, is Vue, rather than React.
I also have a plugin that keeps track of my chats with .specstory.
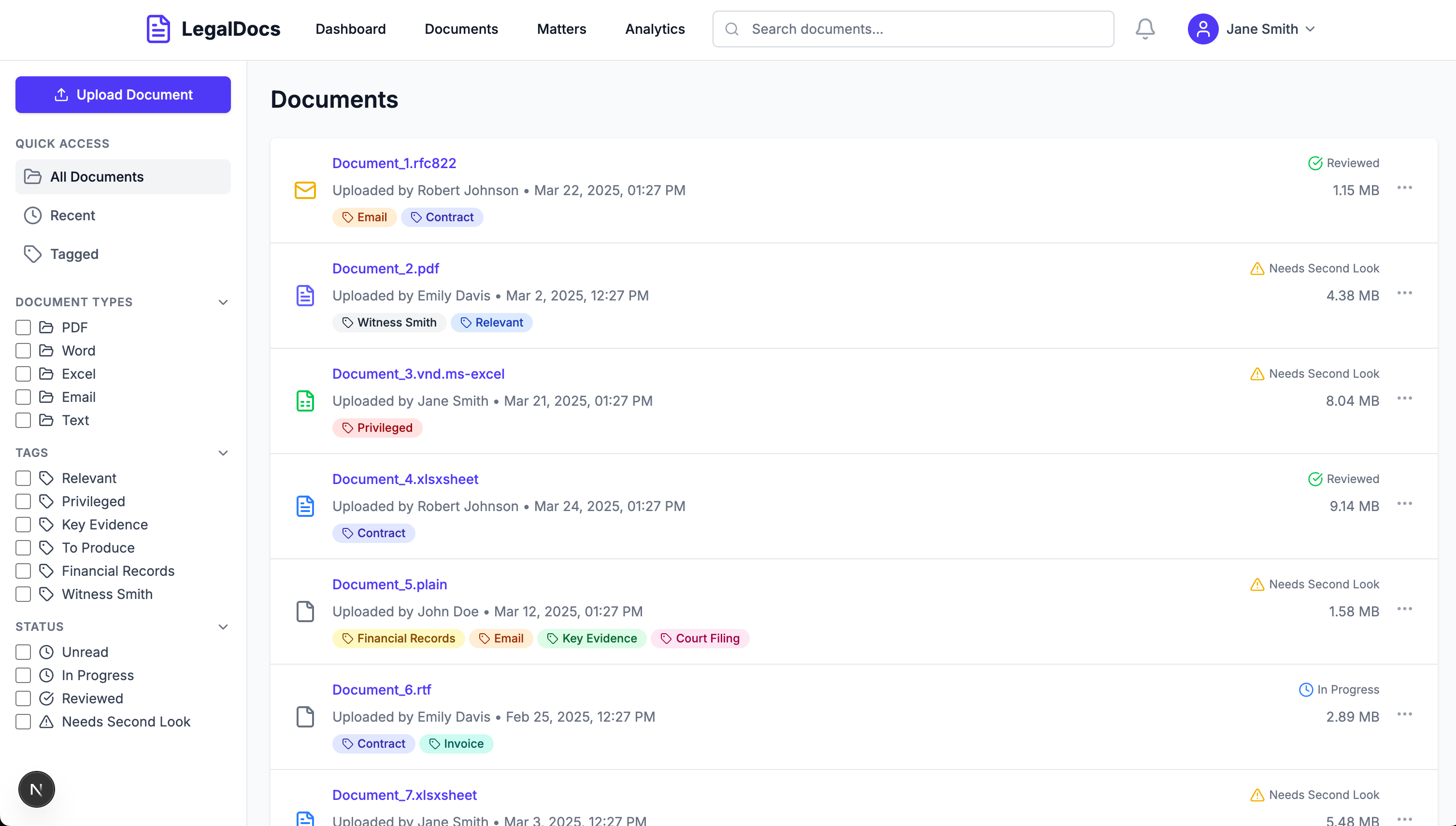
Here’s what we have for now, after letting the Agent do its work (and a fair bit of simple, but repetitive prompting). This is quite different from what one would have been able to expect just a year ago.
Anyway, Github repo here. We’re not quite there with a snazzy frontend yet.
Till next week!
Listening 🎶: Masayoshi Takanaka, Gilad Hekselman
Reading 📖: Careless People: A Cautionary Tale of Power, Greed, and Lost Idealism